4.7. 流水线并行¶
4.7.1. 简介¶
通常来讲,训练更大规模的网络模型可以在多种任务上取得更好的效果,如提升图像分类任务的准确率。然而,训练更大规模的网络模型会消耗更多的显存资源,甚至是超过单个设备的显存容量,从而导致模型无法训练。流水线并行通过将网络模型不同的层放置到不同的设备,从而降低单个设备的显存消耗,使得超大规模模型训练成为可能。本文主要介绍飞桨流水线并行的基本原理和使用方法。
4.7.2. 原理介绍¶
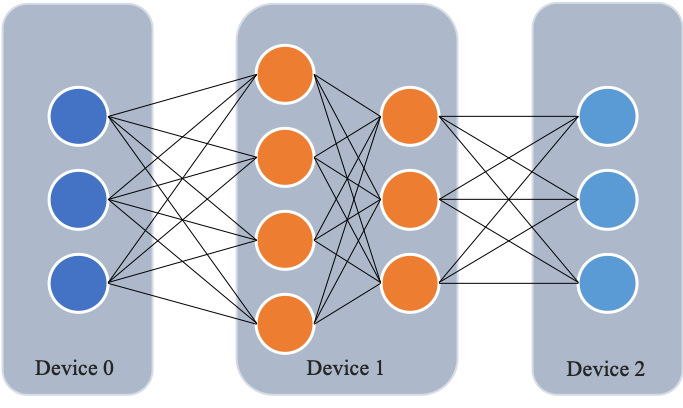
与数据并行不同,流水线并行将模型的不同层放置到不同的计算设备,降低单个计算设备的显存消耗,从而实现超大规模模型训练。以上图为例,示例模型包含四个模型层。该模型被切分为三个部分,并分别放置到三个不同的计算设备。即,第1层放置到设备0,第2层和第三3层放置到设备1,第4层放置到设备2。相邻设备间通过通信链路传输数据。具体地讲,前向计算过程中,输入数据首先在设备0上通过第1层的计算得到中间结果,并将中间结果传输到设备1,然后在设备1上计算得到第2层和第3层的输出,并将模型第3层的输出结果传输到设备2,在设备2上经由最后一层的计算得到前向计算结果。反向传播过程类似。最后,各个设备上的网络层会使用反向传播过程计算得到的梯度更新参数。由于各个设备间传输的仅是相邻设备间的输出张量,而不是梯度信息,因此通信量较小。
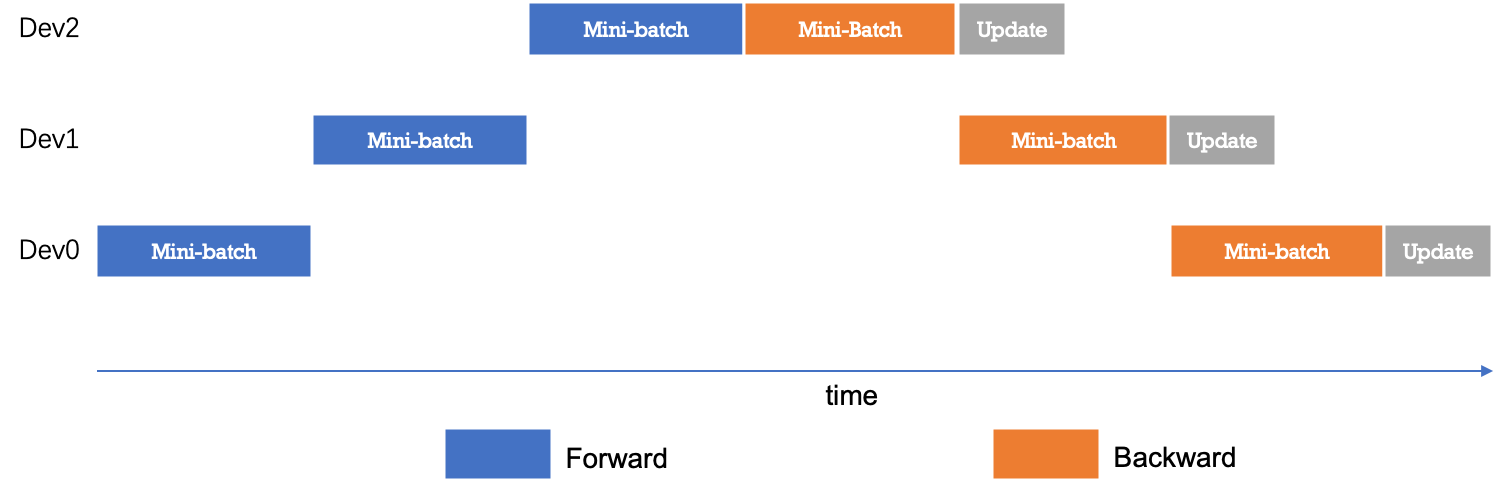
下图给出流水线并行的时序图。最简配置流水线并行模型下,任意时刻只有单个计算设备处于计算状态,其它计算设备则处于空闲状态,因此设备利用率和计算效率较差。
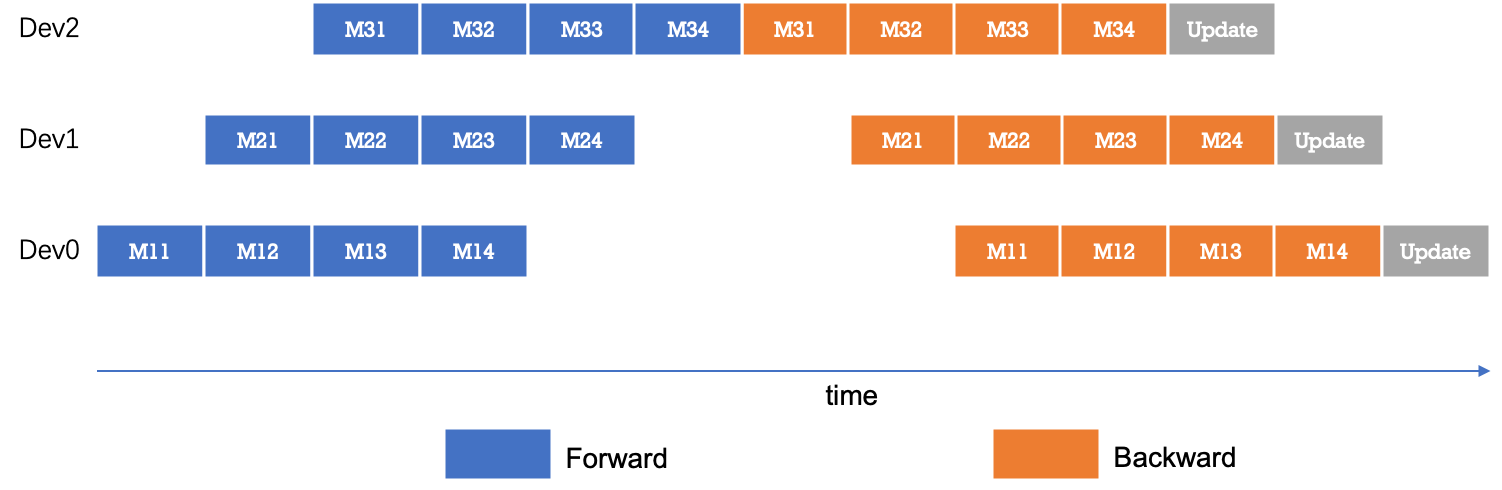
为了优化流水线并行中设备的计算效率,可以进一步将mini-batch切分成若干更小粒度的micro-batch,以提升流水线并行的并发度,进而达到提升设备利用率和计算效率的目的。如下图所示,一个mini-batch被切分为4个micro-batch;前向阶段,每个设备依次计算单个micro-batch的结果;从而增加了设备间的并发度,降低了流水线并行bubble空间比例,提高了计算效率。
4.7.3. 功能效果¶
使用流水线并行,可以实现超大规模模型训练。例如,使用多个计算设备,可以实现单个计算设备显存无法容纳的模型训练。
4.7.4. 静态图使用方法¶
在使用流水线并行的训练策略时,我们通过device_guard接口将不同的计算层放置在不同的设备上,如device_guard("gpu:0")。需要注意的是,当前流水线并行仅支持GPU设备。并且,模型中每个层都需要指定放置设备。
# device_guard 使用示例
def build_network():
with paddle.fluid.device_guard("gpu:0"):
data = paddle.static.data(name='sequence', shape=[1], dtype='int64')
data_loader = paddle.io.DataLoader.from_generator(
feed_list=[data],
capacity=64,
use_double_buffer=True,
iterable=False)
emb = nn.embedding(input=data, size=[128, 64])
with paddle.fluid.device_guard("gpu:1"):
fc = nn.fc(emb, size=10)
loss = paddle.mean(fc)
return data_loader, loss
通过设定dist_strategy.pipeline 为True,将流水线并行的策略激活。
fleet.init(is_collective=True)
dist_strategy = paddle.distributed.fleet.DistributedStrategy()
dist_strategy.pipeline = True
进一步地,可以通过dist_strategy.pipeline_configs 配置流水线并行中mini-batch的切分粒度。假设mini-batch的大小为128,可以通过下述代码将mini-batch切为4份更小粒度的micro-batch,每个micro-batch的大小为32。需要注意地是,用户需要保证mini-batch大小是micro-batch大小的整数倍。
fleet.init(is_collective=True)
dist_strategy = paddle.distributed.fleet.DistributedStrategy()
strategy.pipeline_configs = {"accumulate_steps": 4,
"micro_batch_size": 32}
基于ResNet50网络的流水线并行代码:example/resnet。
使用下述命令行运行示例代码:
python -m paddle.distributed.launch \
--gpus="0,1,2,3" \
train_fleet_pipeline.py
控制台输出信息如下:
WARNING 2021-01-08 15:53:27,677 launch.py:314] Not found distinct arguments and compiled with cuda. Default use collective mode
launch train in GPU mode
INFO 2021-01-08 15:53:27,679 launch_utils.py:471] Local start 5 processes. First process distributed environment info (Only For Debug):
+=======================================================================================+
| Distributed Envs Value |
+---------------------------------------------------------------------------------------+
| PADDLE_TRAINER_ID 0 |
| PADDLE_CURRENT_ENDPOINT 127.0.0.1:52033 |
| PADDLE_TRAINERS_NUM 5 |
| PADDLE_TRAINER_ENDPOINTS ... 0.1:12178,127.0.0.1:28915,127.0.0.1:32114|
| FLAGS_selected_gpus 0 |
+=======================================================================================+
INFO 2021-01-08 15:53:27,679 launch_utils.py:475] details abouts PADDLE_TRAINER_ENDPOINTS can be found in log/endpoints.log.
grep: warning: GREP_OPTIONS is deprecated; please use an alias or script
server not ready, wait 3 sec to retry...
not ready endpoints:['127.0.0.1:40388', '127.0.0.1:12178', '127.0.0.1:28915', '127.0.0.1:32114']
server not ready, wait 3 sec to retry...
not ready endpoints:['127.0.0.1:12178']
W0108 15:53:37.673019 103703 device_context.cc:342] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1
W0108 15:53:37.678391 103703 device_context.cc:352] device: 0, cuDNN Version: 7.6.
日志信息位于log目录下,log/workerlog.4日志文件的内容如下:
grep: warning: GREP_OPTIONS is deprecated; please use an alias or script
W0108 15:52:27.723405 103188 device_context.cc:342] Please NOTE: device: 4, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1
W0108 15:52:27.728278 103188 device_context.cc:352] device: 4, cuDNN Version: 7.6.
I0108 15:52:32.665313 103188 gen_nccl_id_op_helper.cc:176] Server listening on: 127.0.0.1:32347 successful.
W0108 15:52:36.874132 103188 operator.cc:1194] Device index is only supported under pipeline parallelism, so it will be ignored.
grep: warning: GREP_OPTIONS is deprecated; please use an alias or script
W0108 15:53:31.393914 103723 device_context.cc:342] Please NOTE: device: 4, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1
W0108 15:53:31.398906 103723 device_context.cc:352] device: 4, cuDNN Version: 7.6.
I0108 15:53:34.465754 103723 gen_nccl_id_op_helper.cc:176] Server listening on: 127.0.0.1:32114 successful.
W0108 15:53:40.784844 103723 operator.cc:1194] Device index is only supported under pipeline parallelism, so it will be ignored.
[Epoch 0, batch 5] loss: 0.37770, acc1: 0.03125, acc5: 0.03125
[Epoch 0, batch 10] loss: 0.06200, acc1: 0.00000, acc5: 0.03125
[Epoch 0, batch 15] loss: 0.26105, acc1: 0.00000, acc5: 0.00000
[Epoch 0, batch 20] loss: 0.00000, acc1: 0.00000, acc5: 0.00000
[Epoch 0, batch 25] loss: 0.37330, acc1: 0.00000, acc5: 0.06250
[Epoch 0, batch 30] loss: 0.00000, acc1: 0.00000, acc5: 0.00000
[Epoch 0, batch 35] loss: 0.07487, acc1: 0.00000, acc5: 0.00000
[Epoch 0, batch 40] loss: 0.12932, acc1: 0.03125, acc5: 0.06250
[Epoch 0, batch 45] loss: 0.19604, acc1: 0.00000, acc5: 0.03125
[Epoch 0, batch 50] loss: 0.07977, acc1: 0.00000, acc5: 0.00000
[Epoch 0, batch 55] loss: 0.00000, acc1: 0.00000, acc5: 0.00000
[Epoch 0, batch 60] loss: 0.13464, acc1: 0.00000, acc5: 0.06250
[Epoch 0, batch 65] loss: 0.13940, acc1: 0.00000, acc5: 0.03125
[Epoch 0, batch 70] loss: 0.00000, acc1: 0.00000, acc5: 0.00000
[Epoch 0, batch 75] loss: 0.00000, acc1: 0.00000, acc5: 0.00000
4.7.5. 注意事项¶
由于流水线并行将模型的层放置到不同的计算设备,因此在fetch信息时,只有所fetch的数据所在设备进程对应的日志信息中输出数据信息,其它设备进程对应的日志输出None。以上面的示例说明,由于获取的损失值和精度值只在最后一个设备上,因此只有log/workerlog.4日志文件中会输出对应的数据,其它日志文件不会输出对应的数据。
4.7.6. 动态图使用方法¶
流水线并行根据执行的策略,可以分为F then B 和 1F1B 两种模式,目前Paddle动态图流水线只支持1F1B模式。
下面代码在Paddle2.0以上可以运行,建议将Paddle版本升级到最新版
首先导入需要的包
import numpy as np
import os
import paddle
from paddle.distributed import fleet
from paddle.fluid.dygraph.container import Sequential
import paddle.nn as nn
from paddle.fluid.dygraph.layers import Layer
from paddle.distributed.fleet.meta_parallel import LayerDesc, PipelineLayer
import paddle.nn.functional as F
import paddle.distributed as dist
import random
然后构造一个普通的AlexNet模型, 作为对比
class ReshapeHelp(Layer):
def __init__(self, shape):
super(ReshapeHelp, self).__init__()
self.shape = shape
def forward(self, x):
return x.reshape(shape=self.shape)
class AlexNet(Layer):
def __init__(self, num_classes=10):
super(AlexNet, self).__init__()
self.features = Sequential(
nn.Conv2D(
1, 64, kernel_size=11, stride=4, padding=5),
nn.ReLU(),
nn.MaxPool2D(
kernel_size=2, stride=2),
nn.Conv2D(
64, 192, kernel_size=5, padding=2),
nn.ReLU(),
nn.MaxPool2D(
kernel_size=2, stride=2),
nn.Conv2D(
192, 384, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2D(
384, 256, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2D(
256, 256, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2D(
kernel_size=2, stride=2), )
self.reshape_layer = ReshapeHelp(shape=[-1, 256])
self.classifier = nn.Linear(256, num_classes)
self.loss_fn = nn.loss.CrossEntropyLoss()
def forward(self, x, y):
x = self.features(x)
x = self.reshape_layer(x)
x = self.classifier(x)
return self.loss_fn(x, y)
然后构建一个可以运行流水线的模型,模型的layer需要被LayerDesc或者继承了LayerDesc的SharedLayerDesc包裹,这里因为不需要共享参数,所以就使用LayerDesc
class AlexNetPipeDesc(PipelineLayer):
def __init__(self, num_classes=10, **kwargs):
self.num_classes = num_classes
decs = [
LayerDesc(
nn.Conv2D, 1, 64, kernel_size=11, stride=4, padding=5),
LayerDesc(nn.ReLU),
LayerDesc(
nn.MaxPool2D, kernel_size=2, stride=2),
LayerDesc(
nn.Conv2D, 64, 192, kernel_size=5, padding=2),
F.relu,
LayerDesc(
nn.MaxPool2D, kernel_size=2, stride=2),
LayerDesc(
nn.Conv2D, 192, 384, kernel_size=3, padding=1),
F.relu,
LayerDesc(
nn.Conv2D, 384, 256, kernel_size=3, padding=1),
F.relu,
LayerDesc(
nn.Conv2D, 256, 256, kernel_size=3, padding=1),
F.relu,
LayerDesc(
nn.MaxPool2D, kernel_size=2, stride=2),
LayerDesc(
ReshapeHelp, shape=[-1, 256]),
LayerDesc(nn.Linear, 256, self.num_classes), # classifier
]
super(AlexNetPipeDesc, self).__init__(
layers=decs, loss_fn=nn.CrossEntropyLoss(), **kwargs)
然后初始化分布式环境,这一步主要是构建流水线通信组的拓扑
batch_size = 4
micro_batch_size = 2
strategy = fleet.DistributedStrategy()
model_parallel_size = 1
data_parallel_size = 1
pipeline_parallel_size = 2
strategy.hybrid_configs = {
"dp_degree": data_parallel_size,
"mp_degree": model_parallel_size,
"pp_degree": pipeline_parallel_size
}
strategy.pipeline_configs = {
"accumulate_steps": batch_size // micro_batch_size,
"micro_batch_size": micro_batch_size
}
fleet.init(is_collective=True, strategy=strategy)
为了能够和普通模型的loss进行逐位比较,需要将控制随机变量的种子设置一致
def set_random_seed(seed, dp_id, rank_id):
"""Set random seed for reproducability."""
random.seed(seed)
np.random.seed(seed + dp_id)
paddle.seed(seed + dp_id)
print("seed: ", seed)
print("rank_id: ", rank_id)
print("dp_id: ", dp_id)
hcg = fleet.get_hybrid_communicate_group()
world_size = hcg.get_model_parallel_world_size()
dp_id = hcg.get_data_parallel_rank()
pp_id = hcg.get_stage_id()
rank_id = dist.get_rank()
set_random_seed(1024, dp_id, rank_id)
然后创建出普通模型以及对应的优化器
model_a = AlexNet(10)
scheduler_a = paddle.optimizer.lr.PiecewiseDecay(
boundaries=[2], values=[0.001, 0.002], verbose=False
)
optimizer_a = paddle.optimizer.SGD(learning_rate=scheduler_a, parameters=model_a.parameters())
然后创建出流水线并行的模型,
AlexNetPipeDesc(….):这一步主要是在切分普通模型的layer,将属于当前卡的layer添加到模型里面
fleet.distributed_model(….):这一步则是真正进行流水线模型并行的初始化,会得到之前构建拓扑组已经组建好的流水线通信组,并且如果流水线并行混合了数据并行,模型并行,会对数据并行和模型并行相关参数进行broadcast
fleet.distributed_optimizer(…):这一步则是为优化器添加分布式属性,如果流水线并行混合了数据并行,sharding,就会对相应梯度进行all reduce
model_b = AlexNetPipeDesc(num_stages=pipeline_parallel_size, topology=hcg._topo)
scheduler_b = paddle.optimizer.lr.PiecewiseDecay(
boundaries=[2], values=[0.001, 0.002], verbose=False
)
optimizer_b = paddle.optimizer.SGD(learning_rate=scheduler_b,
parameters=model_b.parameters())
model_b = fleet.distributed_model(model_b)
optimizer_b = fleet.distributed_optimizer(optimizer_b)
流水线并行将模型按layers切分,为了能够和普通模型loss对齐,需要采用热启模式,先保存普通模型的参数,然后流水线并行模型加载相关参数
# 保存普通模型参数
param_len = len(model_a.parameters())
parameters = []
for param in model_a.parameters():
parameters.append(param.numpy())
# 流水线并行模型加载参数
for idx, param in enumerate(model_b.parameters()):
param.set_value(parameters[idx + pp_id * (param_len // 2)])
创建mnist数据集
train_reader = paddle.batch(
paddle.dataset.mnist.train(), batch_size=batch_size, drop_last=True
)
开始训练
model_b.train_batch(…):这一步主要就是执行1F1B的流水线并行方式
for step_id, data in enumerate(train_reader()):
x_data = np.array([x[0] for x in data]).astype("float32").reshape(
batch_size, 1, 28, 28
)
y_data = np.array([x[1] for x in data]).astype("int64").reshape(
batch_size, 1
)
img = paddle.to_tensor(x_data)
label = paddle.to_tensor(y_data)
img.stop_gradient = True
label.stop_gradient = True
if step_id >= 5:
break
loss_a = model_a(img, label)
loss_a.backward()
optimizer_a.step()
optimizer_a.clear_grad()
scheduler_a.step()
loss_b = model_b.train_batch([img, label], optimizer_b, scheduler_b)
print("single_loss: ", loss_a.numpy(), "pp_loss: ", loss_b.numpy())
运行方式(需要保证当前机器有两张gpu):
export CUDA_VISIBLE_DEVICES=0,1
python -m paddle.distributed.launch alexnet_dygraph_pipeline.py # alexnet_dygraph_pipeline.py是用户运行动态图流水线的python文件
基于AlexNet的流水线并行动态图代码:example/alex。
控制台输出信息如下:
WARNING 2021-10-21 14:47:54,245 launch.py:381] Not found distinct arguments and compiled with cuda or xpu. Default use collective mode
launch train in GPU mode!
INFO 2021-10-21 14:47:54,246 launch_utils.py:525] Local start 2 processes. First process distributed environment info (Only For Debug):
+=======================================================================================+
| Distributed Envs Value |
+---------------------------------------------------------------------------------------+
| PADDLE_TRAINER_ID 0 |
| PADDLE_CURRENT_ENDPOINT 127.0.0.1:10101 |
| PADDLE_TRAINERS_NUM 2 |
| PADDLE_TRAINER_ENDPOINTS 127.0.0.1:10101,127.0.0.1:13727 |
| PADDLE_RANK_IN_NODE 0 |
| PADDLE_LOCAL_DEVICE_IDS 0 |
| PADDLE_WORLD_DEVICE_IDS 0,1 |
| FLAGS_selected_gpus 0 |
| FLAGS_selected_accelerators 0 |
+=======================================================================================+
日志信息位于log目录下:
single_loss: [2.299683] pp_loss: [2.2996738]
single_loss: [2.287039] pp_loss: [2.2870412]
single_loss: [2.3449194] pp_loss: [2.3449283]
single_loss: [2.3162396] pp_loss: [2.3162327]
single_loss: [2.3100634] pp_loss: [2.310072]
4.7.7. 注意事项¶
与静态图的流水线不一样的是每张卡都会输出loss,并且流水线loss的值是相等的,与普通模型的loss在小数点后三位应该是相等的。