整体介绍与内容概览¶
近十年来,深度学习技术不断刷新视觉、自然语言处理、语音、搜索和推荐等领域任务的记录。这其中的原因,用一个关键词描述就是“大规模”。大规模的数据使得模型有足够的知识可以记忆,大规模参数量的模型使得模型本身有能力记忆更多的数据,大规模高性能的算力(以GPU为典型代表)使得模型的训练速度有百倍甚至千倍的提升。大规模的数据、模型和算力作为深度学习技术的基石,在推动深度学习技术发展的同时,也给深度学习训练带来了新的挑战:大规模数据和大规模模型的发展使得深度学习模型的能力不断增强,如何更加合理地利用大规模集群算力高效地训练,这是分布式训练需要解决的问题。
飞桨分布式从产业实践出发,提供参数服务器(Parameter Server)和集合通信(Collective)两种主流分布式训练构架,具备包括数据并行、模型并行和流水线并行等在内的完备的并行能力,提供简单易用地分布式训练接口和丰富的底层通信原语,赋能用户业务发展。
下面,我们总体介绍飞桨分布式能力和整体文档组织结构。
飞桨分布式训练提供的核心价值¶
源自产业实践的经验¶
飞桨分布式训练技术源自百度的业务实践,在自然语言处理、计算机视觉、搜索和推荐等领域经过超大规模业务检验。基于产业实践,飞桨分布式支持参数服务器和集合通信两种主流分布式训练架构:
参数服务器架构:该架构对于存储超大规模模型参数的训练场景十分友好,常被用于训练拥有海量稀疏参数的搜索推荐领域模型。
集合通信架构:该架构往往是由高算力计算芯片通过高速网络互联而成,如高性能计算的 GPU之间的高速网络互联 NVLINK 和 InfiniBand等,因此非常适合 CV 和 NLP 领域的计算密集型训练任务。
下面将进一步详细介绍这两种架构。
参数服务器架构¶
参数服务器是一种编程范式,方便用户分布式编程。参数服务器架构的重点是对模型参数的分布式存储和协同支持。参数服务器架构如下图所示,集群中的节点分为两种角色:计算节点(Worker)和参数服务器节点(Server)。
Worker负责从参数服务节点拉取参数,根据分配给自己的训练数据计算得到参数梯度,并将梯度推送给对应的Server。
Server负责存储参数,并采用分布式存储的方式各自存储全局参数的一部分,同时接受Worker的请求查询和更新参数。
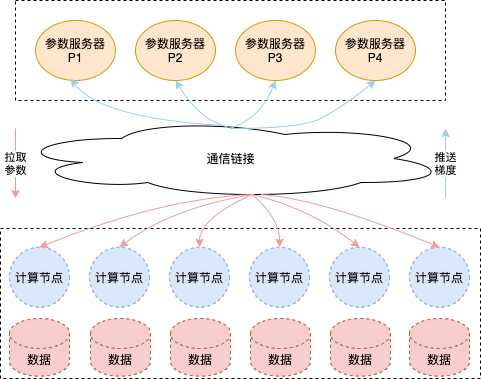
具体地讲,参数服务器架构下,模型参数分配到所有的参数服务器节点,即每个服务器节点上只保存部分的模型参数。在高可靠性要求场景下,也可以将每个参数在多个参数服务器节点中进行备份。每个计算节点上的计算算子都是相同的(即数据并行),完整的数据集被切分到每个计算节点,每个计算节点使用本地分配的数据进行计算:在每次迭代中,计算节点从参数服务器节点拉取参数用于训练本地模型,计算完成后得到对应参数的梯度,并把梯度上传给参数服务器节点更新参数。参数服务器节点获取计算节点传输的梯度后,将汇总并更新参数。
集合通信架构¶
与参数服务器架构具有两种角色不同,集合通信架构中所有的训练节点通常是对等的,可以说都是Worker。节点间通过Collective集合通信原语通信,因此也称为Collective训练,如下图所示。一种典型的集合通信原语是基于NVIDIA NCCL通信库的集合通信原语。集合通信架构的典型应用方式是使用多张GPU卡协同训练,典型应用场景包括计算机视觉和自然语言处理等。
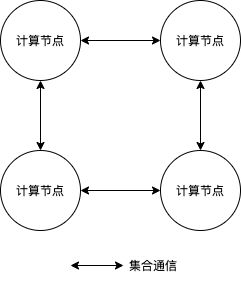
典型应用场景下,如数据并行模式下,数据集也是切分到各个计算节点,每个计算节点中包含完整的模型参数,并根据本地训练数据训练模型,并得到本地梯度,随后所有计算节点使用集合通信原语获取全局梯度,并更新参数。
完备的并行模式¶
数据、算法和算力是深度学习从理论走向实践的关键因素。单纯从算力的角度看,大规模算力增长主要体现在两个方面:一方面,单个计算设备(如GPU)的算力逐年递增;另一方面,大规模计算集群使得集群整体算力急剧增长。单个设备算力的增长降低了同等规模模型的训练时间。然而,随着互联网和大数据技术的发展,可供模型训练的数据集极速扩增。例如,自然语言处理任务的数据集可达数TB。单个设备完成模型训练的时间需要数月或更多。因此,大规模计算集群的使用进一步加速了训练进程。例如,使用2048张Tesla P40 GPU可以在4分钟内完成ImageNet训练[1]。从算法的角度讲,规模更大的模型可以取得更好的效果。例如,更大规模的语言模型在文章补全、问答系统和对话系统等自然语言处理任务中起着重要作用。通常来讲,有两种方式来扩展模型规模:一种是增加模型的层数,即模型的深度;另一种是增加模型隐层的大小,即模型的宽度。然而,训练这类大规模模型的显存需求远远超过主流GPU的单卡显存容量。例如,OpenAI发布的GPT-3模型具有175B参数量[2];当采用FP32格式存储时,仅存储模型参数就需要700GB显存。因此,为了训练超大规模模型,需要使用流水线并行、张量模型并行和Sharding并行等并行技术。
飞桨分布式提供以下并行技术,实现训练的加速和高效的大规模模型训练。
数据并行:每个计算设备上包含完整的模型副本,因此要求模型训练时的显存需求不超过计算设备的显存容量。在深度学习模型训练过程中,前向计算和反向传播阶段会生成大量的中间状态(Activation),这些中间状态的显存占用和batch size成正比。数据并行可以看作从batch size维度进行切分,通过将较大的batch size切分到
N个计算设备上,使得每个计算设备上中间状态的显存开销降到原来的1/N,从而可以训练更大的模型。然而,数据并行存在以下极限:当每个计算设备上的batch size为1时,如果模型训练的显存消耗仍然超过单个计算设备的显存容量,则数据并行无能无力,需要使用流Sharding、流水线并行、张模型并行或者是混合并行技术。更多信息请参考数据并行。张量模型并行:张量模型并行将同一张量切分到不同计算设备,解决大规模模型训练显存需求超过单个计算设备显存容量的问题,并实现高效的大规模模型训练。然而,张量模型并行模式下,通信无法和计算重叠,因此通常将张量模型并行限制在单机内,以利用机内的高通信带宽。更多信息请参考张量模型并行。
流水线并行:增加模型层数是扩展模型规模一种方式;流水线并行是将模型按层拆分到不同计算设备,以流水线的方式逐层完成训练计算任务,从而解决大规模模型训练显存需求超过单个计算设备显存容量的问题,并实现高效的大规模模型训练。因为,不同切分间通信的数据量仅为切分间的中间状态,通信量较小,因此通常将流水线并行应用到机间。更多信息请参考流水线并行。
Sharding并行:Sharding并行本质上是一种数据并行。与数据并行存在多份模型参数副本不同,Sharding并行通过参数切分,确保模型参数在多个设备间只存在一个副本,降低数据并行的显存消耗,实现大规模模型训练。然而,Sharding并行的通信量为三倍的参数量,因此通常适用于机器数较少的训练场景。通常来讲,当参数规模为百亿或以下时,可以使用Sharding并行。当参数规模达到千亿或者更大时,则建议使用基于张量模型并行、流水线并行的混合并行方式。更多信息请参考使用Sharding训练超大模型。
混合并行:通常来讲,不太建议单独使用张量模型并行和流水线并行,而应该在参数规模较大时(如千亿规模以上)采用张量模型并行、流水线并行和数据并行等组合的混合并行,以充分利用机内和机间存储和带宽,实现高效的模型训练。更多信息请参考飞桨4D混合并行训练使用指南。
综上所述,可以参考如下的流程图选择您需要的并行模式。

更多关于每种并行模式特性和如何根据模型特性选择对应的并行模式,请参考飞桨4D混合并行训练使用指南。
开始你的分布式训练之旅¶
整体内容:我们推荐您直接根据主页,按照章节顺序逐个浏览学习,如果有任何疑问都可以在Paddle、PaddleFleetX提交issue提问。
快速上手:如果想最低成本的了解飞桨的分布式训练,我们推荐阅读GPU多机多卡(Collective)训练快速开始和参数服务器训练快速开始。
GPU多机训练:如果您已经开始使用GPU进行多机多卡训练,Collective训练包含了诸多飞桨多机多卡的训练能力和优化方法,建议阅读。
参数服务器:信息检索、推荐系统领域常用的并行训练方式,参数服务器训练包含了飞桨参数服务器的训练能力,建议阅读。
性能基准:可以参考性能基准章节获取飞桨分布式性能数据。
FAQ:对于高频出现的问题,我们会定期整理相关内容到FAQ。