启动分布式任务¶
飞桨通过paddle.distributed.launch组件启动分布式任务。该组件可用于启动单机多卡分布式任务,也可以用于启动多机多卡分布式任务。该组件为每张参与分布式任务的训练卡启动一个训练进程。默认情形下,该组件将在每个节点上启动N个进程,这里N等于训练节点的卡数,即使用所有的训练卡。用户也可以通过gpus参数指定训练节点上使用的训练卡列表,该列表以逗号分隔。需要注意的是,所有节点需要使用相同数量的训练卡数。
为了启动多机分布式任务,需要通过ips参数指定所有节点的IP地址列表,该列表以逗号分隔。需要注意的是,该列表在所有节点上需要保持一致,即各节点IP地址出现的顺序需要保持一致。
例如,可以通过下面的命令启动单机多卡分布式任务,假设节点包含8张GPU卡:
python -m paddle.distributed.launch --gpus 0,1,2,3,4,5,6,7 train.py --batch_size=64
其中,train.py为用户训练脚本,后面可进一步增加脚本参数,如batch size等。用户也可以只使用部分卡进行训练。例如,下面的例子中,仅使用2、3两张卡进行训练:
python -m paddle.distributed.launch --gpus 2,3 train.py --batch_size=64
从单机到多机分布式任务,只需额外指定ips参数即可,其内容为多机的IP列表。假设两台机器的IP地址分别为192.168.0.1和192.168.0.2,那么在这两个节点上启动多机分布式任务的命令如下所示:
# 第一个节点
python -m paddle.distributed.launch --gpus="0,1,2,3,4,5,6,7" --ips="192.168.0.1,192.168.0.2" train.py --batch_size=64
# 第二个节点
python -m paddle.distributed.launch --gpus="0,1,2,3,4,5,6,7" --ips="192.168.0.1,192.168.0.2" train.py --batch_size=64
需要注意的是,两个节点上ips列表的顺序需要保持一致。用户也可使用gpus参数指定每个节点上只使用部分训练卡,命令如下所示:
# 第一个节点
python -m paddle.distributed.launch --gpus=0,1,2,3 --ips="192.168.0.1,192.168.0.2" train.py --batch_size=64
# 第二个节点
python -m paddle.distributed.launch --gpus=0,1,2,3 --ips="192.168.0.1,192.168.0.2" train.py --batch_size=64
两个节点上可以使用不同的训练卡进行训练,但需要使用相同数量的训练卡。例如,第一个节点使用0、1两张卡,第二个节点使用2、3两张卡,启动命令如下所示:
# 第一个节点
python -m paddle.distributed.launch --gpus=0,1 --ips="192.168.0.1,192.168.0.2" train.py --batch_size=64
# 第二个节点
python -m paddle.distributed.launch --gpus=2,3 --ips="192.168.0.1,192.168.0.2" train.py --batch_size=64
下面将介绍paddle.distributed.launch组件在不同场景下的详细使用方法。
Collective分布式任务¶
Collective分布式任务场景下,paddle.distributed.launch组件支持以下参数:
usage: launch.py [-h] [--log_dir LOG_DIR]
[--run_mode RUN_MODE] [--gpus GPUS] [--ips IPS]
training_script ...
启动分布式任务
optional arguments:
-h, --help 给出该帮助信息并退出
Base Parameters:
--log_dir LOG_DIR 训练日志的保存目录,默认:--log_dir=log/
--run_mode RUN_MODE 任务运行模式, 可以为以下值: collective/ps/ps-heter;
当为collective模式时可省略。
--gpus GPUS 训练使用的卡列表,以逗号分隔。例如: --gpus="4,5,6,7"
将使用节点上的4,5,6,7四张卡执行任务,并分别为每张卡
启动一个任务进程。
training_script 用户的任务脚本,其后为该任务脚本的参数。
training_script_args 用户任务脚本的参数
Collective Parameters:
--ips IPS 参与分布式任务的节点IP地址列表,以逗号分隔,例如:
192.168.0.16,192.168.0.17
各个参数的含义如下:
log_dir:训练日志储存目录,默认为
./log目录。该目录下包含endpoints.log文件和各个卡的训练日志workerlog.x(如workerlog.0,wokerlog.1等),其中endpoints.log文件记录各个训练进程的IP地址和端口号。run_mode:运行模式,如collecitve,ps(parameter-server)或者ps-heter。
gpus:每个节点上使用的gpu卡的列表,以逗号间隔。例如
--gpus="0,1,2,3"。需要注意:这里的指定的卡号为物理卡号,而不是逻辑卡号。training_script:训练脚本,如
train.py。training_script_args:训练脚本的参数,如batch size和学习率等。
ips:所有训练节点的IP地址列表,以逗号间隔。例如,
--ips="192.168.0.1,192.168.0.2。需要注意的是,该列表在所有节点上需要保持一致,即各节点IP地址出现的顺序在所有节点的任务脚本中需要保持一致。
通过paddle.distributed.launch组件启动分布式任务,将在控制台显示第一张训练卡对应的日志信息,并将所有的日志信息保存到log_dir参数指定的目录中;每张训练卡的日志对应一个日志文件,形式如workerlog.x。
PaddleCloud平台¶
当在百度内部PaddleCloud平台使用飞桨分布式时,可以省略ips参数。假设使用两台机器执行分布式任务,则命令行如下所示:
# 第一台机器:
python -m paddle.distributed.launch --gpus="0,1,2,3,4,5,6,7" train.py
# 第二台机器:
python -m paddle.distributed.launch --gpus="0,1,2,3,4,5,6,7" train.py
更多关于如何通过在PaddleCloud上启动分布式任务,请参考PaddleCloud官方文档。
物理机或docker环境启动分布式任务¶
我们以下面的场景为例说明如何在物理机环境或者docker环境中启动飞桨分布式任务。假设我们有两台机器,每台机器包含4张GPU卡。两台机器的IP地址分别为192.168.0.1和192.168.0.2。该IP地址可以为两台物理机的IP地址,也可以为两台机器内部Docker容器的IP地址。
为了在两台机器上启动分布式任务,首先需要确保两台机器间的网络是互通的。可以通过ping 命令验证两台机器间的网络互通性,如下所示:
# 第一个节点
ping 192.168.0.2
# 第二个节点
ping 192.168.0.1
如果两台机器间的网络无法连通,请联系您的网络管理员获取帮助。
假设用户的训练脚本为train.py,则可以通过如下命令在两台机器上启动分布式训练任务:
# 第一台机器:192.168.0.1
python -m paddle.distributed.launch --gpus="0,1,2,3" --ips="192.168.0.1,192.168.0.2" train.py
# 第二台机器:192.168.0.2
python -m paddle.distributed.launch --gpus="0,1,2,3" --ips="192.168.0.1,192.168.0.2" train.py
当每台机器均使用所有4张训练卡时,也可以省略gpus参数,如下所示:
# 第一台机器:192.168.0.1
python -m paddle.distributed.launch --ips="192.168.0.1,192.168.0.2" train.py
# 第二台机器:192.168.0.2
python -m paddle.distributed.launch --ips="192.168.0.1,192.168.0.2" train.py
用户也可以通过gpus参数指定只使用部分训练卡,例如只使用0、1两张卡:
# 第一台机器:192.168.0.1
python -m paddle.distributed.launch --gpus="0,1" --ips="192.168.0.1,192.168.0.2" train.py
# 第二台机器:192.168.0.2
python -m paddle.distributed.launch --gpus="0,1" --ips="192.168.0.1,192.168.0.2" train.py
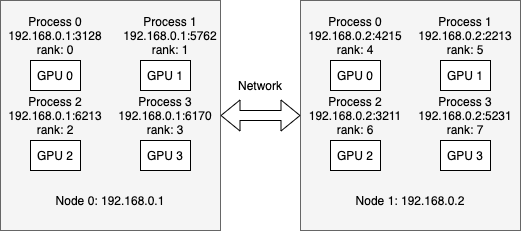
通过paddle.distributed.launch组件启动分布式任务时,该组件将为gpus参数指定的每张训练卡启动一个训练进程。为了实现进程间通信,该组件同时为每个进程绑定一个端口号,进程的IP地址和端口号成为该进程的网络地址。paddle.distributed.launch组件随机查找机器上的可用端口,作为训练进程的端口号。假设,Node 0上4个训练进程的端口号分别为3128、5762、6213和6170,则该机器上4个训练进程的网络地址分别为: 192.168.0.1:3128、192.168.0.1:5762、192.168.0.1:6213和192.168.0.1:6170。当paddle.distributed.launch组件无法获取足够的可用端口时,任务启动失败。
日志信息说明¶
首先,我们介绍一些基本概念。我们使用world_size或nranks(number of ranks)表示分布式任务使用的卡的总数,使用N表示每台机器上使用的卡数,使用M表示分布式任务使用的总机器数;那么,\(world\_size=N*M\)。按照机器在ips参数中出现的顺序,每台机器被赋予一个节点id:M_id,这里\(0<=M\_id<M\)。例如,假设,ips参数为”192.168.0.1,192.168.0.2”,那么以192.168.0.1为IP地址的机器在ips参数列表的索引为0,故其M_id为0。同理,以192.168.0.2为IP地址的机器在ips参数列表的索引为1,故其M_id为1。同样的,我们根据每台机器上训练卡在gpus参数列表出现的顺序为其赋予一个卡id:N_id,这里\(0<=N\_id<N\)。例如,假设gpus参数为”2,3”,那么卡2的N_id为0,卡3的N_id为1。我们也可以将N_id称为local_rank。我们为每张训练卡赋予唯一的标识:rank,这里\(0<=rank<world\_size\)。一般来讲,我们可以通过如下的公式计算每张卡的rank值。
这里,需要注意local_rank和rank的区别:local_rank是局部的,在同一机器内部是唯一的,但是不同机器上的卡可以具有相同的local_rank;而rank是全局唯一的,同一任务中所有的卡具有不同的rank值。
通过paddle.distributed.launch组件启动分布式任务时,将在终端打印rank值为0的卡对应的训练日志信息,而其余所有卡对应的训练日志信息保存在log_dir指定的目录中。该目录下存在两类文件:endpoints.log和workerlog.id,这里id表示卡的rank值,如workerlog.0、workerlog.1 等。需要注意的是,日志目录中只会保存该机器上所有卡的训练日志,而不会保存其它机器上卡的训练日志。因此,需要登录到对应机器上,以查看相应卡的训练日志。
其中,endpoints.log中记录所有训练进程的网络地址,示例如下:
PADDLE_TRAINER_ENDPOINTS:
192.168.0.1:3128
192.168.0.1:5762
192.168.0.1:6213
192.168.0.1:6170
192.168.0.2:4215
192.168.0.2:2213
192.168.0.2:3211
192.168.0.2:5231
需要说明的是,当多次启动分布式任务时,训练是以追加的方式追加到日志文件中的。因此,在查看日志信息时,请注意查看相应任务对应的日志信息。一般情况下,可以直接跳转到文件末尾,以查看最近任务的日志信息。在调试时,为了避免信息干扰,一种方法是在每次启动分布式任务前清空日志目录。
报错信息说明¶
这里,我们对分布式任务中常见的一类报错信息进行说明,方便用户快速定位错误信息。
一般在用户分布式任务出错时,控制台会输出如下信息:
"ABORT!!! Out of all 8 trainers, the trainer process with rank=[2,3] was aborted. Please check its log.".
上述信息给出分布式任务的world_size为8,其中rank值为2和3的进程终止。因此,通过上述信息,用户可以快速判断出错的进程,并查看相应的训练日志获取更多错误信息。例如,可以直接查看workerlog.2和workerlog.3两个进程的错误日志,获取更多错误信息。
当训练日志包含如下信息时,通常表明其它训练进程出错,导致当前训练进程被中断。也就是说,用户需要查看其它训练进程的日志信息获取更多任务失败原因。
[SignalInfo: *** SIGTERM (@0x3fe) received by PID 1164 (TID 0x7f6cf1fc6700) from PID 1022 ***]
例如,某用户在排查报错信息时,发现workerlog.0日志中存在上述信息。进一步查看其它进程的日志信息,最终在workerlog.4中发现如下报错信息,进而定位出错原因是数据读取出错。
2021-11-03 05:08:55,091 - ERROR - DataLoader reader thread raised an exception!
Error: [Errno 5] Input/output error
Traceback (most recent call last):
File "/root/paddlejob/workspace/env_run/reader.py", line 218, in __next__
data = next(self, loader)
File "/usr/local/lib/python3.7/site-packages/paddle/fluid/dataloader/dataloader_iter.py", line 779, in __next__
data = self._reader.read_next_var_list()
SystemError: (Fatal) Blocking queue is killed because the data reader raises an exception.
[Hint: Expected killed_ != true, but received killed_:1 == true:1.] (at /paddle/paddle/fluid/operators/reader/blocking_queue.h:158)
ParameterServer分布式任务¶
ParameterServer相关参数如下:
--servers: 多机分布式任务中,指定参数服务器服务节点的IP和端口,例如 --servers="192.168.0.16:6170,192.168.0.17:6170"。
--workers: 多机分布式任务中,指定参数服务器训练节点的IP和端口,也可只指定IP,例如 --workers="192.168.0.16:6171,192.168.0.16:6172,192.168.0.17:6171,192.168.0.17:6172"。
--heter_workers: 在异构集群中启动分布式任务,指定参数服务器异构训练节点的IP和端口,例如 --heter_workers="192.168.0.16:6172,192.168.0.17:6172"。
--worker_num: 单机模拟分布式任务中,指定参数服务器训练节点的个数。
--server_num: 单机模拟分布式任务中,指定参数服务器服务节点的个数。
--heter_worker_num: 在异构集群中启动单机模拟分布式任务, 指定参数服务器异构训练节点的个数。
--http_port: 参数服务器模式中,用 Gloo 启动时设置的连接端口。
Elastic 参数¶
--elastic_server: etcd 服务地址 host:port,例如 --elastic_server=127.0.0.1:2379。
--job_id: 任务唯一 ID,例如 --job_id=job1。
--np: 任务 pod/node 编号,例如 --np=2。
--host: 绑定的主机,默认等于 POD_IP 环境变量。